The Memory Layerfor AI Applications
Model-agnostic memory layer that unifies context, cuts costs, and improves retrieval.





Zero-Friction Intelligence Layer
No new adapters. No platform lock-in. No rebuilding your agents. Cortyxia wraps around your existing API key and adds model-agnostic memory, real-time context improvement, and deep AI and Agentic observability — with zero overhead.
We are not a vector store, not a cache layer, and not a band-aid on top of your existing stack. Cortyxia is a purpose-built memory context architecture that lets AI applications remember, reason, and adapt across every conversation. We capture the intent, history, and relationships that make your AI actually useful the next time a user returns — without manual prompt engineering, fragile RAG pipelines, or forcing your data into the wrong database. No retrofitted SQL. No bolted-on Redis. Just persistent context that learns and makes every response sharper.
We do not ask you to connect your tools to us. We do not require new adapters, custom schemas, or middleware rewrites. We do not ask you to build your agents within our platform, stitch together workflows inside our UI, or re-architect your stack around our primitives. Cortyxia wraps around what you already have — your LLM provider, your API keys, your existing integrations, your own agent framework — and enhances them exactly where they run. Zero migration. Zero lock-in. Zero friction.
Think of us as a virtual layer that wraps itself around your LLM provider's API key. Whether you are using N8N, Salesforce, or a custom integration — instead of calling your provider directly, you call them through Cortyxia. We improve context on the fly with efficient memory node construction, management, and retrieval. You get full visibility into prompt metrics, granular tracing, and performance comparisons. Want to switch LLMs? Remove the wrapper and place it on another provider's key. Same intelligence, new engine.
Unified Memory
Cortyxia bridges the intelligence gap between your applications with a single, persistent memory layer.











Cumulative Intelligence
Every resolved ticket and strategic decision enriches your shared memory layer. No need for manual integrations, just select BYOK or BYOLLM, and use Cortyixa enabled API key and auto-connect with Salesforce, HubSpot, Slack, and more. Your entire stack intergrated within minutes, ensuring expertise compounds and insights never decay.
Zero Overhead Setup
No new adapters or platform lock-in. One-click API key swap wraps around your existing infrastructure, adding model-agnostic memory and real-time context improvement without rebuilding your agents.
Bidirectional Synchronization
Real-time bidirectional synchronization keeps every connected enterprise app in lockstep. Update once, reflect everywhere instantly. Your data flows seamlessly across your ecosystem.
OSuite Observability
Four lenses into every inference. Compare models, audit prompts, examine guardrails, and trace every step — all in one pane.
Model Comparison
Benchmark every model across cost, latency, and token usage. Track 6 quality metrics — hallucination, groundedness, drift, relevance, safety, and accuracy — in a unified leaderboard.
Prompt Metrics
See how each prompt fares between models on the 6 core metrics. Spot weak prompts, compare outputs side-by-side, and optimize what you send to the LLM.
Tracer
Full granular visibility into every message. Trace tool calls, memory searches, context retrieval, and agent reasoning across the entire pipeline — no black boxes, full accountability.
Guardrail Check
Auto-detect behavior and guardrails, ranging from positive to tone to styling, and more — from 'you are a marketing bot' to 'do not mention Topic X'. Every message pair is checked for compliance with full violation traces.
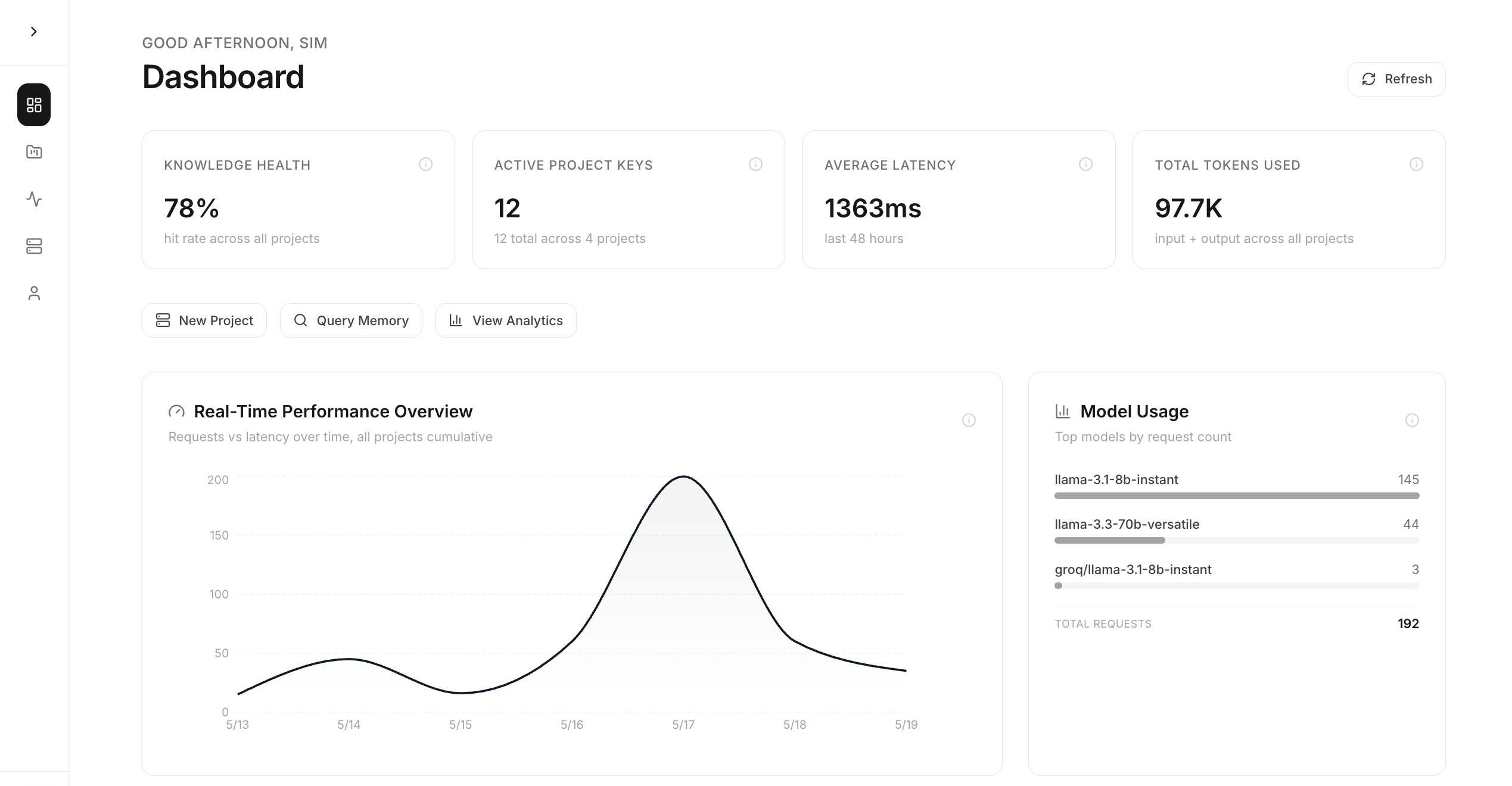
Knowledge Health Centre
Surface missing information from across your organization. See which business functions your AI handles well — and where institutional knowledge is missing.
Intelligence Coverage Map
A comprehensive view of your organization's knowledge health across all business functions. Track coverage gaps, detect stale signals, identify blind spots, and prioritize acquisition where no relevant memory was found in recent queries.
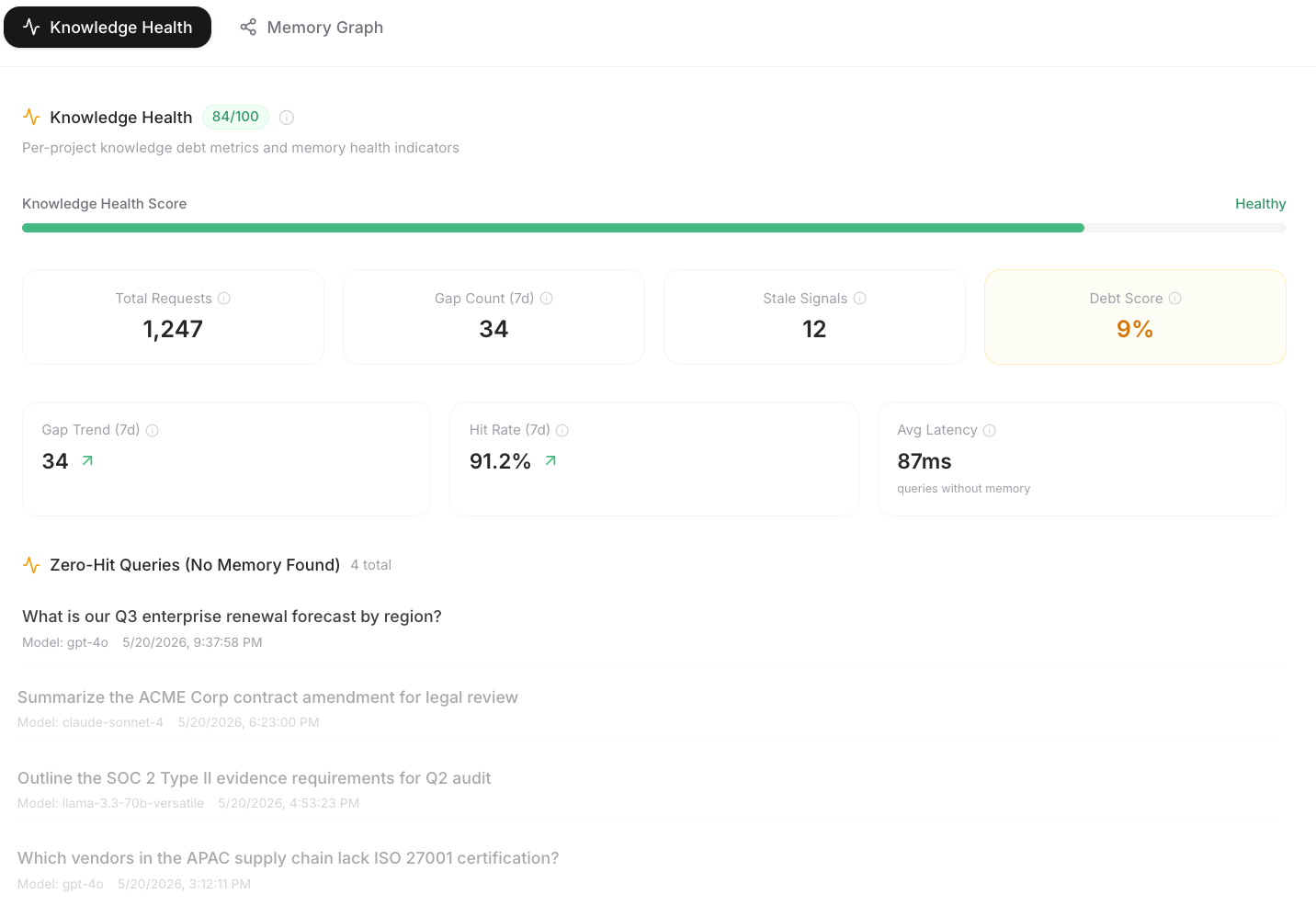
Memory Nodes and Connections
Get an in-depth view of memory nodes, connection density, and how far clusters spread. Surface over-retrieved hotspots, under-retrieved gaps, and exact areas where related knowledge needs reinforcement.
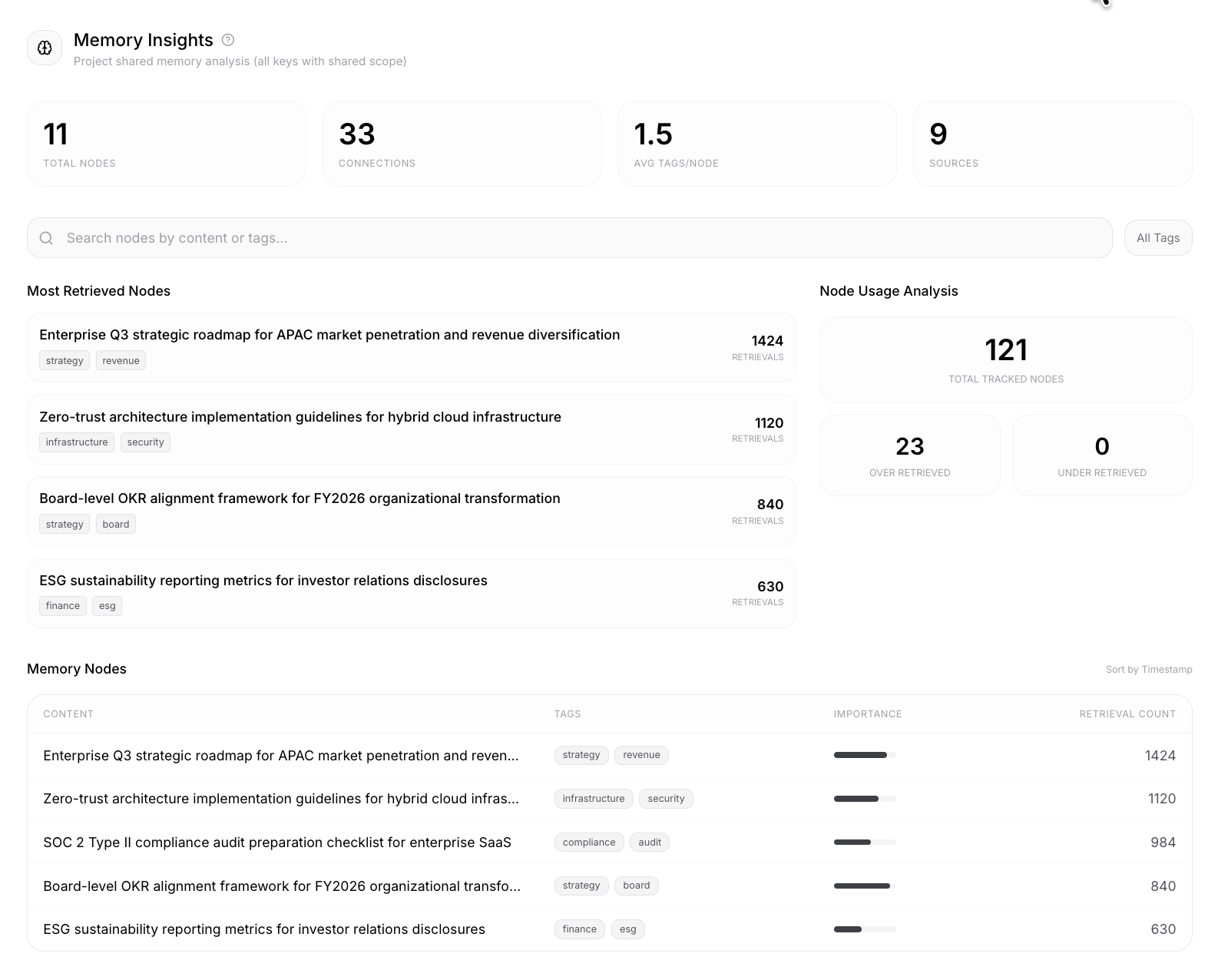
Token-Efficient Memory
Isolated namespaces and precision retrieval keep every project in scope and every prompt lean. No wasted tokens, no cross-contamination.
Pooled Memory
Multiple API keys feeding into the same memory pool, or keep each key locked to its own isolated context. You decide what converges across teams and what stays private — no duplication, no leakage.
Precision Retrieval
Semantic relevance scoring surfaces exactly the memory your model needs — no more stuffing the full context window. Hot nodes rank higher, stale context gets deprioritized, and prompts stay lean even as your knowledge base grows.
Private Memory Keys
Every project, team, or environment gets its own isolated key. Memory stays scoped and impossible to cross-contaminate.
Observability Mode
ISO architecture keys can run observability-only — you pick which interactions shape your memory and which stay as pure telemetry.
Granular
Infrastructure
Self Host Your Data
Export Your Data for Training
Your Data, Always Yours

Common Questions
Everything you need to know about the future of AI memory management.